Introduction to Kubernetes
Kubernetes is now the de facto container orchestration platform deployed by businesses across the globe. In its short existence it has had incredible growth, being released in 2015 it is now the second-highest project on GitHub – second only to Linux. The huge community of support includes 1.2 million comments, 164,000 commits, and 31,000 contributions. There are quarterly conferences (KubeCon), weekly podcasts, dedicated Slack channels with over 75,000 users and thousands of tutorials available. Companies like IBM, Spotify, CERN and CapitalOne all use Kubernetes to deliver services to their customers – in fact, over 54% of the Fortune 500 (top US 500 companies) use Kubernetes.
Read our introduction to Kubernetes if you want to learn more about the basics.
Prefer to read the kubernetes security best practice article as a pdf? Download below.

What is a container orchestration platform?
In recent years, there has been an architectural shift from deploying monolithic applications to using distributed microservices. This change has made it easier to build and maintain applications, increased scalability, productivity and speed of delivery. The standard pattern now for creating applications is to separate functions based around business capabilities.
This movement has been accelerated thanks to the likes of container technologies such as Docker. Docker is a tool designed to make it easier to create, deploy, and run applications using containers – allowing a developer to package all of the parts it needs, such as libraries and other dependencies, and ship it all out as one package.

Container technologies offer many benefits including
- The ability to deploy a container anywhere and run it reliably,
- Resource efficiency and density – pack more containers onto a physical machine than virtual machines
- Increased security by providing a level of isolation
- Speed; start, create and replicate containers in seconds
- Operational simplicity – no matter what your application is written in, the container conforms to a standard set of principles.
Containers are now used extensively across the IT landscape with some companies deploying hundreds of thousands of them. But how do you manage all of these containers? How do you scale a set of containers up when demand increases on your platform? How do you keep track of your container deployments and ensure they’re always running?
This is what a container orchestration platform has been designed to do.
Back in 2003, Google was in such a place – deploying thousands of containers and struggling to manage all the overheads that came with them. Google started working on a project called Borg which managed all of Google’s container estate and became the inspiration behind Kubernetes. Kubernetes was donated to the Cloud Native Computing Foundation (a body aimed at building sustainable cloud ecosystems) by Google in 2015 and later graduated in 2018.
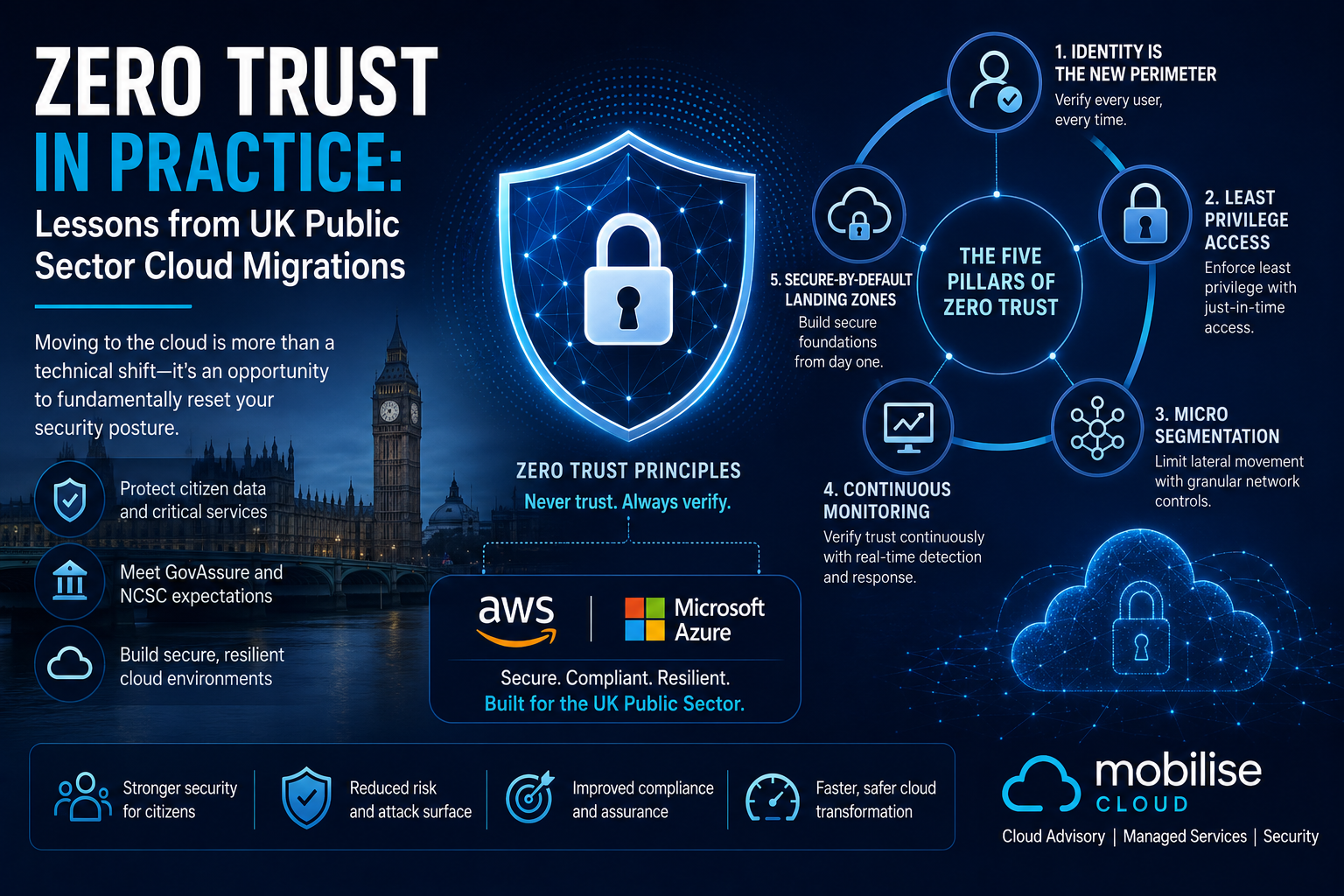
Kubernetes

Kubernetes is a Greek word meaning ‘helmsman’ or ‘pilot’ and is pronounced ‘Koo-burr-NET-eez’ (which can be written as ‘K8s’ for short). This open-source platform is designed to manage containerised workloads and services in an automated, declarative configuration. What this means is that operators can define the desired state of their Kubernetes cluster using YAML and Kubernetes will make changes to enforce that state. Kubernetes takes care of:
- Service discovery and load balancing -distributing traffic between containers using DNS.
- Storage orchestration – handles storage setup and management for containers.
- Automated rollouts and rollbacks – carry out deployments with automated rolling deployments providing zero downtime and easily rollback if needed.
- Automatic bin packing – specify how much CPU and memory a container needs and Kubernetes can organise containers onto specific hosts to ensure minimal wastage in terms of physical host resources.
- Self-Healing – automatic health checking of applications to restart failed containers or kill containers with problems.
- Secret and configuration management- store and manage sensitive information that can be utilised by containers.
Kubernetes Installations
When it comes to deploying Kubernetes, there are several options available: on bare metal, on-premise, and in the public cloud. Kubernetes was designed to be highly portable and customers can easily switch between these installations, migrating their workloads – from on-premise to a cloud provider, for example. When it comes to the public cloud, there are two main options available: deploy a custom Kubernetes build on virtual machines OR use a managed service.
Due to the massive uptake in Kubernetes, public cloud providers now generally provide a Kubernetes managed service. This managed service takes care of the Kubernetes Control Plane, ensuring that updates are applied, and servers are highly available and scaled correctly. However, this comes at a cost both financially and creatively, as users are billed per hour for the managed service and are unable to customise certain aspects of Kubernetes.
Compare the various Managed Kubernetes solutions here.

All of this potential customisation of Kubernetes means it can be designed to fit a large variety of scenarios; however, this is also its greatest weakness when it comes to security. Kubernetes is designed out of the box to be customisable and users must turn on certain functionality to secure their cluster. This means that the engineers responsible for deploying the Kubernetes platform need to know about all the potential attack vectors and vulnerabilities poor configuration can lead to.
Securing your kubernetes cluster
Recently, Kubernetes was in the news for all the wrong reasons: security flaws. The Cloud Native Computing Foundation (CNCF), which looks after Kubernetes, conducted its own security audit into the popular container orchestration tool.

To verify the security of kubernetes, CNCF approached two companies- Trail of Bits and Atredis Partners – to conduct a thorough inspection of the Kubernetes source code over a period of four months. The results of the audit were a little startling with 34 vulnerabilities identified – 4 of which were high severity.
What’s more interesting is their summary of the codebase:
“The assessment team found configuration and deployment of Kubernetes to be non-trivial, with certain components having confusing default settings, missing operational controls, and implicitly designed security controls”
This statement highlights the fact that a deep understanding of Kubernetes is needed in order to deploy highly available and secure Production-ready clusters. One of the main challenges in securing Kubernetes is a large amount of moving parts within the cluster and how they are configured to interact with each other. In a recent interview on the Kubernetes Podcast, Ian Coldwater (A specialist in breaking and hardening Kubernetes) describes the multivariate attack surface of Kubernetes:
“There are so many moving parts interacting with each other in different ways. There are things that can be exposed. There’s any number of things that you can configure, and therefore any number of things that you can misconfigure.”
Ian goes on to explain how Kubernetes’s incredible rate of adoption has exposed some of the security design decisions made when creating Kubernetes. In order to obtain widespread adoption, Kubernetes was designed to be an open system and allow administrators granular control to lock down aspects of the platform. As each installation could vary greatly this decision allowed for the organic growth and take-up of Kubernetes. However, it required administrators to have a detailed understanding of how Kubernetes works, and which features need to be enabled/disabled to establish a secure cluster. As Kubernetes has spread into the mainstream IT landscape it has been used by engineers who are not so familiar with the technology and this has led to insecure installations and exposed attack surfaces.
So, what are the common pitfalls and how do you protect your cluster against them?
Kubernetes Security: Versions control
The first thing an attacker is going to check for is what versions of the software are running in a cluster. What version of Kubernetes is being used? Are there any plugins being used or package software such as Helm? Once identified, the attacker can search for vulnerabilities or common exploits for out of date software.
So, the best practice here is to keep your cluster as up to date as possible – including Kubernetes itself (which regularly release security updates), packages and plugins. This can become a laborious process as Kubernetes is highly customisable and can utilise many different plugins and packages. This means ensuring you have a repeatable, automated patching process in your CI/CD pipeline, so patching doesn’t become a hardship.
If using a Cloud Provider Kubernetes managed service such as Amazons EKS, then this will be taken care of for you and is one of the best selling points of Kubernetes managed services. As well as updating your cluster, it’s vitally important to keep all of the host machines’ OS up to date.
Deployed Applications
Another attack surface is the vulnerabilities of the container applications that are being run on the cluster. When building containers in the CI/CD pipeline they should be pushed to a container registry which is able to scan the images for vulnerabilities. An example of this would be CNCFs open-source registry, Harbor. Harbor is a highly available container registry which uses CNCFs Claire project (vulnerability static analysis for containers) to scan images for vulnerabilities.

Policies should be built into the CI/CD pipeline to prevent the automatic deployment of vulnerable containers and developers notified to patch the container exploits.
Configuration
The Kubernetes platform is controlled using API requests and as such is the first line of defence against attackers. Controlling who has access and what actions they are allowed to perform is the primary concern here.
Use Transport Layer Security
Communication in the cluster between services should be handled using TLS, encrypting all traffic by default. This, however, is often overlooked with the thought being that the cluster is secure and there is no need to provide encryption in transit within the cluster. In the past, it has been difficult to manage certificates and keystores which has led to a mentality of ‘let’s just get it working first and we’ll enable TLS later’.
Advances in network technology, such as the service mesh, have led to the creation of products like LinkerD and Istio which can enable TLS by default while providing extra telemetry information on transactions between services.

Authentication & Authorization
All API clients must be authenticated, even those that are part of the Kubernetes infrastructure. It’s important to choose the right authentication method for the API server to use; this could be a simple certificate for small clusters or, for large clusters where there is greater interaction, companies may wish to integrate an LDAP service.
Once authenticated, every API call is also authorised using Kubernetes Role-Based Access Control (RBAC). RBAC provides fine-grained control to limit specific users or groups to only perform certain actions on specified resources on the cluster. For example, user A may only be allowed to perform “create” actions on deployments – meaning they are unable to delete or describe other resources.
More often than not, the out-of-the-box roles are quite broad and should be used as more of a guide than actually relied upon to secure your cluster. It is vital that RBAC is employed to ensure the principle of least privilege – limiting users and groups to just the tasks they require. Implementing RBAC correctly is a crucial step to securing a cluster, and special consideration should be given to the design of roles. It is therefore important to understand exactly how Kubernetes resources hang together – for example if the goal is to prevent a user from creating pods, then allowing them to create deployments will, in turn, create pods.
Finally, any production-grade cluster should enable authentication and authorisation on kubelet, which, by default, allows unauthenticated access. This involves disabling the default anonymous access and enabling authentication through certificates or API bearer tokens while also splitting authorisation into verb (get, delete, etc.) and resource (proxy, metrics) attributes.
Namespaces
Creating namespaces provides a level of isolation between applications and can be used to establish boundaries between systems. This makes it easier to apply policies to specific namespaces that will only impact the desired applications.
Policies & Resources
When running workloads on the cluster it is essential to protect the cluster from resource-hungry containers. These could be a mixture of poorly built applications (such as Java applications that consume too much memory) or malicious applications (crypto mining applications which consume all available resources). At the very least, these containers could consume too much CPU/memory and starve other applications of resources, but at the most, they could consume all resources on a node and cause the cluster to crash.
These resources can be controlled using two different sets of resource policies: Limit ranges & resource quotas.
Resource quotas apply policy across a namespace to limit all resources in that namespace to cumulative totals. These resources can include CPU, memory, number of pods, services or volumes. This ensures that resources can be evenly distributed between namespaces, or perhaps unevenly distributed e.g. dedicate more resources to an integration test namespace than a development namespace.
Limit ranges apply to individual containers and specify the maximum or minimum size of resources allowed. This ensures that users do not request unreasonably high or low values for things like CPU and memory. If a user doesn’t specify what resources they need for their container, then it will take the defaults specified in the limit range.
Pod Security Policies
These policies also apply to containers and limit which users or service accounts can implement dangerous security settings. The primary goal of security policies is to prevent containers being run as root or in privileged mode – which, if compromised, can lead to access to the host volume. For this reason, applications should be designed to be run as non-root users, and cluster administrators enforce this and other security features using security policies.
Network Policies
Network policies are implemented at the namespace level and allow cluster administrators to limit the traffic between applications, acting as a virtual firewall between containers. Once a network policy is applied to a namespace, all traffic by default is denied and rules must be added to enable traffic between applications.
As a Kubernetes security best practice, network policies should be used specifically on cloud platforms to restrict container access to metadata hosted on instances (which can include credential information).
Cluster Patterns
Etcd
The primary source of data within a Kubernetes cluster is contained within the etdc database. If an attacker gains access to the etcd database, then it is essentially game over for the cluster and the attacker will gain full access/control.
To ensure that this doesn’t happen, there are a couple of actions that can be taken:
- Restrict access to etcd – mutual auth via TLS client certificates should be implemented to ensure strong credentials from the API server to the etcd database.
- Use separate isolated instances for etcd.
- Use Access Control Lists to restrict access to a subset of the keyspace.
Auditing
Auditing is a crucial aspect of any system and provides an indisputable record of events which, in the event of a system attack, can supply vital information on the attacker and resources compromised. As per best practices of any public cloud provider, it is recommended to enable auditing at an account level to monitor cloud resources. Kubernetes also recommends that the beta feature audit logger is enabled, and the audit file archived to a secure server.
Plugins & Packages
As mentioned previously, plugins are a great source to attack as they are often overlooked by administrators looking to update the cluster or the creator of the plugin stops working on it. Plugins also have the ability to alter the security posture of your cluster by extending permissions or gaining access to secrets.
Encryption & Credentials
As is standard practice on public clouds, always encrypt the root and attached volumes of your cluster and ensure any backups taken are also encrypted.
The shorter the lifetime of a credential, the harder it is for an attacker to make use of it. Therefore, ensure that all secrets, certificates and tokens have as short a lifespan as possible, and automate the rolling of these credentials.
Notifications
As has been mentioned previously, it is essential to keep your cluster up to date with the latest releases. In order to do this, either enable automatic minor upgrades on the managed Kubernetes cluster or subscribe to announcements (like the Kubernetes Slack channel) to receive the latest news.
Separate Sensitive Workloads
It is common practice in distributed systems to have dedicated hosts for running a collection of sensitive workloads that are isolated from the main group of applications. This can be achieved either by having a separate dedicated cluster for sensitive workloads or by using node pools. This ensures that if an ordinary application is compromised and the attackers gain access to the host file system, they cannot see sensitive secrets that would have been used by the sensitive workloads.