Amazon’s T2 family of instances are a general type of instance that are widely used throughout the industry providing a cheap baseline level of CPU performance with the ability to burst when needed, these bursts however don’t last forever…
So, is it a good idea to run your Kubernetes cluster on T2? The obvious upsides are cost savings, but what happens when things go wrong…
EKS Single T2 Worker Node
Let’s look at an example of running a Kubernetes cluster on Amazon’s EKS service with a single T2. Medium worker node. For this exercise we’re going to borrow from the Kubernetes Pod Autoscaler to spin up two PHP Apache pods which serve a web page that performs some CPU intensive computations.
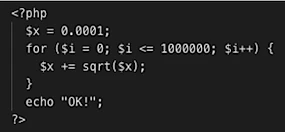
We’re going to request that these pods have 1 vCPU core each – the T2.Medium instances have 2 vCPUs, so you can see that we’re trying to max out the vCPU on the instance.
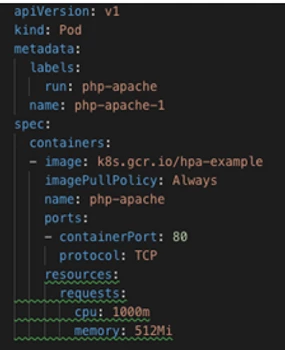
You can see that the editor is already trying to warn us that something is wrong – complaining that we haven’t set any resource limits for the pod (more on this later).
Finally, we’re going to spin up some standard busybox pods that curl the php-apache services indefinitely to generate traffic on the web pages and in turn increase CPU throughput.

he graph below shows the CPU Utilization (Orange) for the T2.Medium worker node as well as the CPU Credit Balance (Blue) and the CPU Credit Usage (Green).
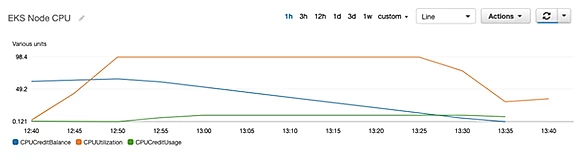
At 12:40 we begin generating load by curling the php-apache services and within ten minutes we’re at roughly 100% CPU utilization, at this point the CPU credits begin to kick in.
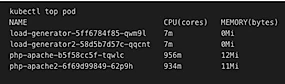
Using metrics server to monitor performance on the EKS cluster we can see our usage.

Now for those of you not familiar with the T2 family – they have a standard CPU baseline dependant on the instance size, for T2.Medium this is 40% (20% per vCPU). Once utilization peaks above this baseline it is effectively ‘bursting’, eating up it’s available CPU credits which in this case is not many as it’s a new instance (T2s build up credits over time).
At 13:25 the instance has all but used its CPU Credits, and without any credits left to burst performance, the instance is throttled down to its baseline. What does this look like in terms of processing power on the php-apache side? Well at ~ 100% CPU utilization we were processing roughly 5 times as many requests than at our throttled ~ 40% CPU.
Now what’s really interesting here is that our Kubernetes monitoring is still showing everything running smoothly…
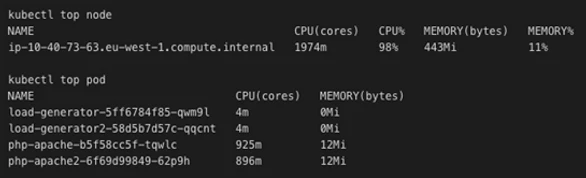
And why not? We’re still getting 100% of our 2vCPU’s as far as Kubernetes is concerned, it just doesn’t know that Amazon has throttled them.
EKS Single T2 Worker Node with Resource Quota
So, we’ve seen that poorly configured pods can consume all the necessary CPU on a worker node, starving other pods from vital resources. Not only does this prevent other applications on the cluster from running correctly but it causes the instance to throttle its CPU and starve all pods.
There are a couple of options to solve this issue if we are to continue using T2s for Kubernetes…
- Add additional worker nodes
- Use unlimited bursting
- Implement resource quotas
The first option is not sustainable as I’m sure we will continue to run out of resources for each node – it’s also more expensive. The second option allows the T2 instance to continue bursting its CPU performance above its credit limit at an additional cost. This option is costly and again doesn’t really solve the underlying issue. The final option is to implement a Kubernetes feature called Resource Quotas which limit pod CPU usage across a namespace. This option is the most sensible approach as it addresses the root cause of the issue and allows us to predictably manage resources on our Kubernetes cluster.
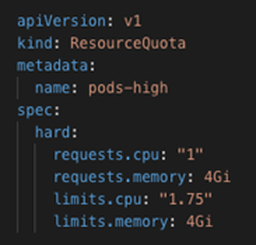
In our resource quota we have defined two sets of variables for our cluster; requests and limits. Requests are used in Kubernetes by the scheduler to determine where it should place the pod in the cluster, limits as the name suggest provide a maximum value a pod can reach for that resource.
Here we’re stating that all pods across the default namespace cannot accumulatively exceed 1 vCPU request (e.g. 5 pods each requesting 0.25) or 1.75 vCPU during the pod’s lifespan. This allows us to keep our vCPU under the instances 2 vCPU limit. Here is what the new apache-php pod manifest looks like with resource quotas applied (note; when a resource quota is applied to a namespace, pods cannot be deployed without declaring a resource request and limit in their manifest)…
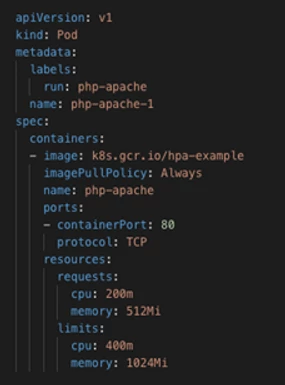
Interestingly if a pod reaches its CPU limit then it will just be throttled at that limit, however if a pod reaches its memory limit it will be identified as a potential process to be killed to avoid Out of Memory issues.
Once we deploy the pods and begin the CPU load generating, we can see the resource quota in action…
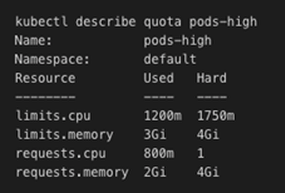
All four of our pods (2 x php-apache, 2 x load-generator) have been successfully deployed as they’re within the agreed resource quota parameters. If we had specified a request for CPU that was too large for example, we would be presented with an error message at deployment time stating there was insufficient resources available.
What does these mean at the AWS instance level?
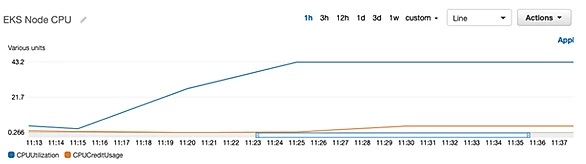
We can see that after spinning up our CPU Load Generator, CPU utilization begins to climb – but levels off at roughly 43% due to the resource quota. The resource quota hasn’t quite saved us completely however – we can see that CPU Credit Usage is starting to climb and levels off around 3. Although this number is small it does mean that we are bursting (above the 40% utilization) and will eventually consume all CPU credits and be throttled to 40% CPU.
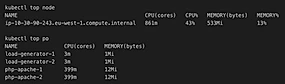
Requests are now being processed at just less than half the original 100% CPU rate.
We could play around with the resource quota to define requests and limits that don’t cause the T2 instance to burst – but then we are hamstringing our Kubernetes cluster by not letting it fully utilise all available resources.
In Summary
We’ve shown that the unpredictable nature of deployments on Kubernetes clusters isn’t a good fit for the T2/3 family of instances. There is the potential to have instances throttled due to pods consuming vast amounts of resources. At best this will limit the performance of your applications and at worst could cause the cluster to fail (if using T2/3s for master nodes) due to ETCD issues. Furthermore, this condition will only be picked up if we are monitoring CloudWatch carefully or performing application performance monitoring on the pods.
To this end it is advisable to avoid using T2/3 instance type families for Kubernetes deployments, if you would like to save money whilst using more traditional instance families (such as Ms and Rs) then take a look at our blog on spot instances.