Introduction
Firstly, allow me to introduce myself. My name is Jeff Owens. I’m a cloud consultant for Mobilise Cloud and I’ve spent a great deal of time working within large, agile cloud transformation projects. I’ve utilised various infrastructure as a code tool, the serverless framework, and helped develop container-based deployments with application teams on Kubernetes & DockerEE. These are deployed and maintained via CI/CD pipelines.
To tell you the truth, when I first started my cloud journey using CI/CD I felt a bit overwhelmed as there was just so much to take in. Not only did I have to learn how to code cloud infrastructure deployments (using terraform and ansible), but I then had to integrate it into automated pipelines! However, believe me when I say that once you start to get the hang of it and experience all the benefits it provides, you won’t look back.
CI/CD is far too wide a subject to cover in a single sitting. In this article, I’ll summarise what I consider to be some of the most important elements and approaches of CI/CD to help improve the effectiveness of your service.
What is CI/CD?
I won’t go into too much detail introducing DevOps, CI/CD and whether it’s for you as this has already been covered by my colleagues’ excellent blog here.
Continuous Integration and Continuous Delivery is the automated process of developing & delivering software/infrastructure in small and fast cycles. If implemented correctly, it will greatly enhance team productivity. Smaller releases and automated testing will enable teams to detect issues or bugs early in the development lifecycle. Moreover, rapid deployment timescales grant the ability to deliver new features in a safe and consistent manner. Automated build and deployments are configured via CI/CD pipelines. It’s essential that you take your time to choose the right CI/CD platform for your organisation and to plan and configure the pipelines correctly. Many CI/CD tools exist, including:
Each product varies in terms of pricing and features. Choosing the right CI/CD and collaboration tools that fit your organisation’s needs can be daunting but it’s certainly a worthwhile investment. As you shift to DevOps you may find promoting the new culture change to other teams just as challenging. Having the right tools in place will make that easier to manage.
The following guidance will hopefully aid you with your transition.
Security
Security is everyone’s responsibility.

Your CI/CD system, in particular, will have access to your codebase and credentials and will therefore be a prime target for attack. For that reason, it’s imperative that you secure it as much as possible. If your organisation has a DevOps framework, you really should be focusing on DevSecOps as a mindset. The whole premise of DevSecOps is that you design & incorporate application & infrastructure security from the start. It also aims at automating security within your development lifecycle as much as possible.
Some high-level security points to think about:
- Isolate your CI/CD system – make it accessible from your internal network only.
- Understand your applications and lockdown any unnecessary open ports (think AWS Security Groups, Firewalls etc.)
- RBAC – manage user/application access effectively and provide the least privileged access wherever possible.
- Vulnerability maintenance
- Maintain a patching strategy to keep on top of any potential new vulnerabilities within your system.
- Code scanning – your source code could contain bugs/vulnerabilities that are hard to miss. Consider incorporating code scanning software into your development strategy (scan before deployment phase). SonarQube is a great example of what can be utilised.
- Docker image scanning tools.
- Protect credentials and sensitive data that are required by your code.
The latter point leads us to the next section – managing secrets & sensitive data outside your code.
Secrets / Sensitive Data
You should always be mindful of the data you push through your code, even when using private git repositories within your own company. You don’t want to inadvertently leak sensitive information to unauthorised users.
The definition of secrets/sensitive information can cover a wide range, but I’ll use the following examples in my case:
- Docker image registry password
- Database passwords
- Certificates
- AWS Access Key ID/Secret Access Key of an AWS user account (in cases where AWS instance profiles/IAM roles cannot be used)
To emphasise, think of the potential damage caused if your Terraform AWS user keys were leaked. Terraform is infrastructure as a code used to provision and manage cloud infrastructure/services. The role and policies associated with the user would typically allow the provision and modification of a number of AWS resources. Obtaining those keys would provide that person similar access. This could prove a very costly mistake – not only financially but also to your organisations reputation!
Options – Environment Variables
The good news is that there are many options around this. In fact, most CI/CD applications have built in functions that allow secrets to be sourced from environment variables that are encrypted within its own database. Examples:
- GitLab uses global and local Environment Variables
- Drone.io uses secrets
Sourcing your secrets & environment variables into your pipeline has many benefits, including:
- No hard-coded secrets (increased security)
- Variables can be used dynamically which leads to repeatable code and easier password rotations etc. (increased manageability and maintainability)
Options – Secret Management Services
Other options include the widely known Hashicorp Vault and the ability to access secrets programmatically from Cloud specific secret management services, such as:
- AWS secret manager/parameter store
- Azure Key Vault
- Google Cloud Berglas/Secret Manager
Typically, these secrets are stored and retrieved via code, API or CLI.
Options – Container based platforms
There are also plenty of options for DevOps engineers working with container-based platforms such as Kubernetes, but my current preferred method is GoDaddy’s opensource Kubernetes-external-secrets. This option supports a number of cloud secret manager services and Hashicorp Vault.
I recommend that you play around with secret management to ascertain which one is right for you and your CI/CD implementation. If it’s secure, manageable and integrates within your pipeline then that’s a great start.
Code Visibility

Large projects will involve multiple developers working together. Therefore, changes should always be maintained via code and pushed to a central repository using a version control system like Git. This will help cement confidence within your organisation. If a change does go wrong, you should have the ability to simply revert back to the previous version (or rapidly produce code and deploy fixes) due to the code tracking Git provides. Moreover, your peers will be required to review and approve your feature branch merges to master. This provides an opportunity for others to either learn from you, suggest improvements or highlight issues in your code.
Making manual changes or deploying code without the correct CI/CD process may cause issues further down the line. In these cases, whilst the issue may be resolved for now, there’s no visibility or repeatability alongside it. Another developer may push their changes out and potentially overwrite those manual fixes. The issue re-appears, leading the new author to believe that it was their changes that caused the issue. This starts to lead support engineers down a rabbit hole and invest critical resource time that could be used elsewhere.
Commits and merge requests should be descriptive at all times to enable other users to understand the intent of your code. More so because you rely on them to review and approve your changes so that you can move on to the deployment phase. The key here is to reduce lead times as much as possible.
Documentation
Probably everyone’s least favourite job, but you really should be producing clear documentation for every repository. You can create README files on each repository and your teammates will love you for it. Here’s a great summary from GitHub:
A README is often the first item a visitor will see when visiting your repository. README files typically include information on:
- What the project does
- Why the project is useful
- How users can get started with the project
- Where users can get help with your project
- Who maintains and contributes to the project
I suggest you write a few notes about how the project integrates within your CI/CD, what to expect (steps & potential timeframes) and how to promote to production.
Branch / Deployment Strategy
If you adopt an Agile methodology, your sprint tasks would typically be assigned in small chunks and each task would be assigned a reference code. In my experience, feature branching using those references seems to be the most effective. As a result, branches are easily identifiable to other members of the team as they can be tied to specific sprint tasks. Whatever you decide, it’s important that you:
- Keep branches to a minimum.
- Merge to Master often – complete the task –> merge to Master –> delete branch.
- Apply feature branches to a development environment only.
- Production environments should only contain deployments from Master branches (and tagged appropriately), and the same mentality should be used for image creations and promotions to container repositories.
CI/CD Pipelines

Automated run events
Your CI/CD pipelines can be configured in a way to run specific tasks as part of a particular git webhook. A basic example using Terraform deployments:
- Changes to code pushed to feature branch
- Pipeline runs on push to feature branch event
- Run Terraform Validate (checks if code is valid)
- Run Terraform Plan – Development Environment
- Run Terraform Plan – NonProd Environment
- Run Terraform Plan – Prod Environment
- Runs terraform deploy to Development Environment only
- Deployment stage runs Kitchen/Inspec automated testing
- User merges to Master – deletes feature branch
- Run Terraform Plan – NonProd
- Run Terraform Plan – Prod Environment
- Await Manual Execution of NonProd Environment only
- The user executes deployment to NonProd
- Deployment stage runs Kitchen/Inspec automated testing
- Tag master branch – merge commit
- Run Terraform Plan – NonProd
- Run Terraform Plan – Prod Environment
- Await Manual Execution of NonProd Environment
- Await Manual Execution of Prod Environment
- User can run both executions for consistency. Git tag (x.x.x) is applied to cloud resource tags for info
- Deployment stage runs Kitchen/Inspec automated testing
The pipeline workflow you use can be tailored to suit your needs. For example, you may decide to automatically execute deployment on NonProd following a Merge to Master (as opposed to waiting for a manual execution).
Test Automation
When you integrate test automation into your CI/CD pipeline you free up team productivity. Less time is spent manually testing so they can focus more on the code itself. With that said, it’s worth noting that you may find that not all tests can be automated. You’ll need to think about your implementation and ascertain which tests fall into both categories. For tests that can’t be automated, it’s worth noting the manual steps in repository’s readme.
Keep it fast
CI is meant to be fast – developers shouldn’t be disrupted by waiting times. Prioritise your test cases by running the smaller/less intensive tests first e.g code linting/SonarQube.
Release often – make use of development and nonprod environments for your tests to ensure your code is ready to be deployed to production.
Linting
‘Linting’ is a term used for the automated analysis of your source code for programmatic and stylistic errors. In other words, they can be used within your pipeline to enforce language-specific best practices and code formatting.
The program that does the linting is referred to as a ‘lint’ or ‘linter’ and are available for most common programming languages.
Minimise Duplication
It’s likely that you’re already experiencing the benefits of minimising duplication in your code using the DRY (Don’t Repeat Yourself) principle. But did you know that you could also apply this to your CI/CD pipelines? A large number of CI/CD tools use yaml files for their pipeline configuration. If your pipeline is yaml based, consider using yaml anchors. Your pipeline steps will inevitably contain repeatable code – incorporating clever methods like these will ultimately reduce maintenance effort.
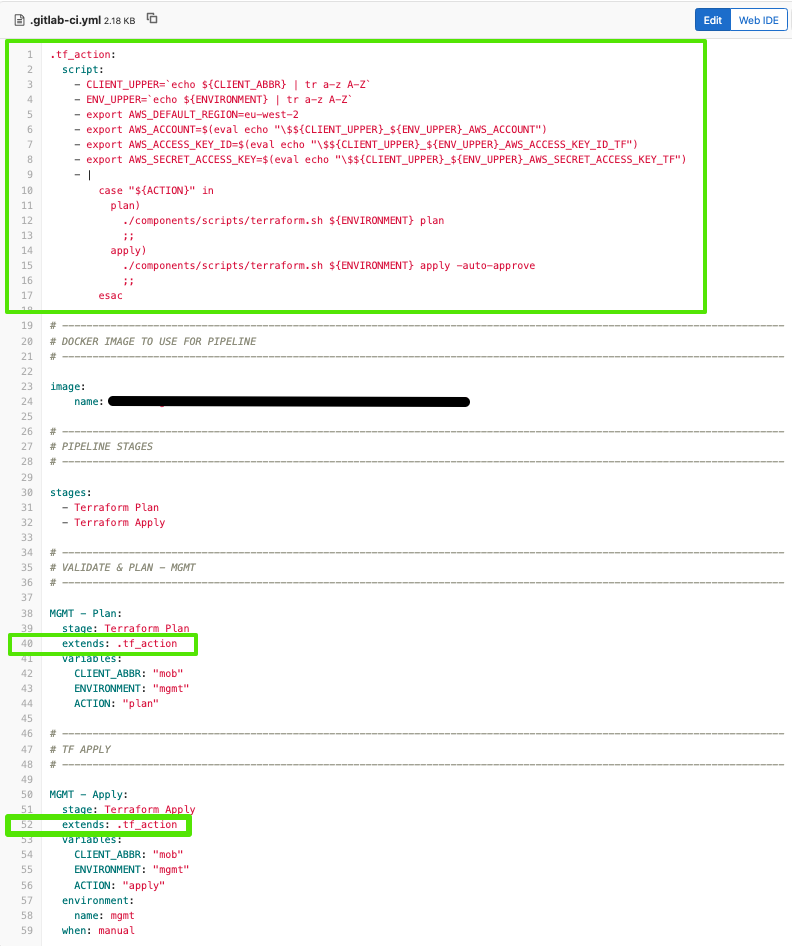
Your CI/CD software may have alternative built in options available. Gitlab, for example, replaces yaml anchors with ‘extends’, but the same premise applies. This is a fairly basic example of a terraform pipeline using extends. It loads specific AWS credentials based on the environment variable configured in the pipeline – the ‘.tf_action’ is defined once but is used by both pipelines:
Tagging

Git Tagging
Consistency is key here. You should adopt a coherent tag/version control strategy and maintain this within your infrastructure/application code. Mobilise practise semantic versioning, but the method you use is ultimately the decision of your organisation and what suits your needs.
Determine whether your image build & deployment pipelines can be automated by git tag events to increase agility.
Utilising CI/CD predefined variables to tag
Many CI/CD solutions generate predefined environment variables as part of the pipeline runtime (e.g. start time, git commit ID, git author etc.). As an experienced Terraform user, I love harnessing these types of variables to tag Cloud infrastructure resources:
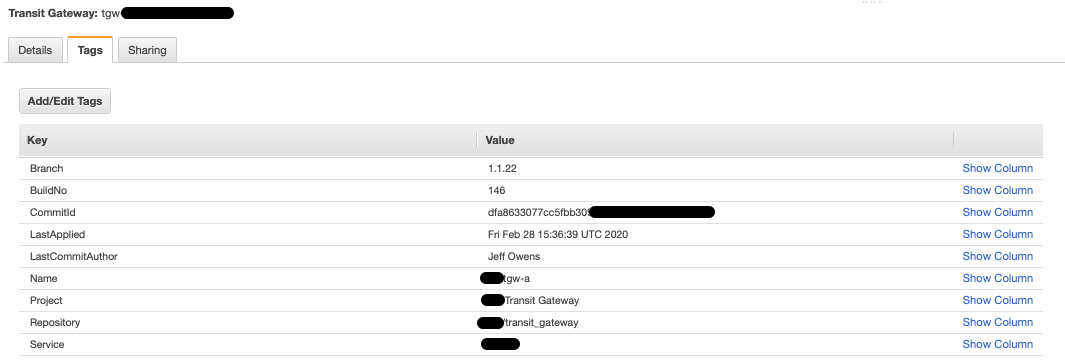
The aim here is to enhance user experience as much as we can. As your environment grows, your code may be split out into multiple repositories and this is when resource tags become very useful. From a cloud engineer perspective, we know which git tag has been deployed, where the source code lives, when it was last deployed and the engineer who made the change. This is just one example, but hopefully it will give you some ideas of where you might utilise your CI/CD predefined variables.
Conclusion
There are many aspects of CI/CD to consider but the key to a successful platform is planning ahead. Remember that the primary goal of DevOps and CI/CD is to automate the development and delivery of software/infrastructure in small and fast cycles. Many tools exist that can help you with this process but you need to find the ones that best fit your organisation and proposed release strategy. Whatever tools you decide to implement, security should always be your first priority.